Derivative
In calculus, a branch of mathematics, the derivative is a measure of how a function changes as its input changes. Loosely speaking, a derivative can be thought of as how much one quantity is changing in response to changes in some other quantity; for example, the derivative of the position of a moving object with respect to time is the object's instantaneous velocity.
The derivative of a function at a chosen input value describes the best linear approximation of the function near that input value. For a real-valued function of a single real variable, the derivative at a point equals the slope of the tangent line to the graph of the function at that point. In higher dimensions, the derivative of a function at a point is a linear transformation called the linearization.[1] A closely related notion is the differential of a function.
The process of finding a derivative is called differentiation. The reverse process is called antidifferentiation. The fundamental theorem of calculus states that antidifferentiation is the same as integration. Differentiation and integration constitute the two fundamental operations in single-variable calculus.
Contents |
Differentiation and the derivative
Differentiation is a method to compute the rate at which a dependent output y changes with respect to the change in the independent input x. This rate of change is called the derivative of y with respect to x. In more precise language, the dependence of y upon x means that y is a function of x. This functional relationship is often denoted y = ƒ(x), where ƒ denotes the function. If x and y are real numbers, and if the graph of y is plotted against x, the derivative measures the slope of this graph at each point.
The simplest case is when y is a linear function of x, meaning that the graph of y against x is a straight line. In this case, y = ƒ(x) = m x + b, for real numbers m and b, and the slope m is given by
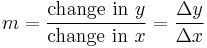
where the symbol Δ (the uppercase form of the Greek letter Delta) is an abbreviation for "change in." This formula is true because
- y + Δy = ƒ(x+ Δx) = m (x + Δx) + b = m x + b + m Δx = y + mΔx.
It follows that Δy = m Δx.
This gives an exact value for the slope of a straight line. If the function ƒ is not linear (i.e. its graph is not a straight line), however, then the change in y divided by the change in x varies: differentiation is a method to find an exact value for this rate of change at any given value of x.
The idea, illustrated by Figures 1-3, is to compute the rate of change as the limiting value of the ratio of the differences Δy / Δx as Δx becomes infinitely small.
In Leibniz's notation, such an infinitesimal change in x is denoted by dx, and the derivative of y with respect to x is written
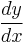
suggesting the ratio of two infinitesimal quantities. (The above expression is read as "the derivative of y with respect to x", "d y by d x", or "d y over d x". The oral form "d y d x" is often used conversationally, although it may lead to confusion.)
The most common approach[2] to turn this intuitive idea into a precise definition uses limits, but there are other methods, such as non-standard analysis.[3]
Definition via difference quotients
Let ƒ be a real valued function. In classical geometry, the tangent line to the graph of the function ƒ at a real number a was the unique line through the point (a, ƒ(a)) that did not meet the graph of ƒ transversally, meaning that the line did not pass straight through the graph. The derivative of y with respect to x at a is, geometrically, the slope of the tangent line to the graph of ƒ at a. The slope of the tangent line is very close to the slope of the line through (a, ƒ(a)) and a nearby point on the graph, for example (a + h, ƒ(a + h)). These lines are called secant lines. A value of h close to zero gives a good approximation to the slope of the tangent line, and smaller values (in absolute value) of h will, in general, give better approximations. The slope m of the secant line is the difference between the y values of these points divided by the difference between the x values, that is,
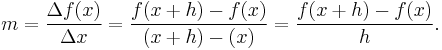
This expression is Newton's difference quotient. The derivative is the value of the difference quotient as the secant lines approach the tangent line. Formally, the derivative of the function ƒ at a is the limit
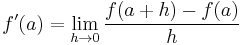
of the difference quotient as h approaches zero, if this limit exists. If the limit exists, then ƒ is differentiable at a. Here ƒ′ (a) is one of several common notations for the derivative (see below).
Equivalently, the derivative satisfies the property that
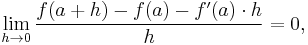
which has the intuitive interpretation (see Figure 1) that the tangent line to ƒ at a gives the best linear approximation
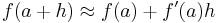
to ƒ near a (i.e., for small h). This interpretation is the easiest to generalize to other settings (see below).
Substituting 0 for h in the difference quotient causes division by zero, so the slope of the tangent line cannot be found directly using this method. Instead, define Q(h) to be the difference quotient as a function of h:
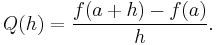
Q(h) is the slope of the secant line between (a, ƒ(a)) and (a + h, ƒ(a + h)). If ƒ is a continuous function, meaning that its graph is an unbroken curve with no gaps, then Q is a continuous function away from h = 0. If the limit 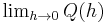 exists, meaning that there is a way of choosing a value for Q(0) that makes the graph of Q a continuous function, then the function ƒ is differentiable at a, and its derivative at a equals Q(0).
exists, meaning that there is a way of choosing a value for Q(0) that makes the graph of Q a continuous function, then the function ƒ is differentiable at a, and its derivative at a equals Q(0).
In practice, the existence of a continuous extension of the difference quotient Q(h) to h = 0 is shown by modifying the numerator to cancel h in the denominator. This process can be long and tedious for complicated functions, and many shortcuts are commonly used to simplify the process.
Example
The squaring function ƒ(x) = x² is differentiable at x = 3, and its derivative there is 6. This result is established by calculating the limit as h approaches zero of the difference quotient of ƒ(3):
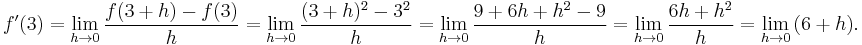
The last expression shows that the difference quotient equals 6 + h when h ≠ 0 and is undefined when h = 0, because of the definition of the difference quotient. However, the definition of the limit says the difference quotient does not need to be defined when h = 0. The limit is the result of letting h go to zero, meaning it is the value that 6 + h tends to as h becomes very small:
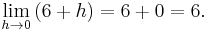
Hence the slope of the graph of the squaring function at the point (3, 9) is 6, and so its derivative at x = 3 is ƒ '(3) = 6.
More generally, a similar computation shows that the derivative of the squaring function at x = a is ƒ '(a) = 2a.
Continuity and differentiability
If y = ƒ(x) is differentiable at a, then ƒ must also be continuous at a. As an example, choose a point a and let ƒ be the step function that returns a value, say 1, for all x less than a, and returns a different value, say 10, for all x greater than or equal to a. ƒ cannot have a derivative at a. If h is negative, then a + h is on the low part of the step, so the secant line from a to a + h is very steep, and as h tends to zero the slope tends to infinity. If h is positive, then a + h is on the high part of the step, so the secant line from a to a + h has slope zero. Consequently the secant lines do not approach any single slope, so the limit of the difference quotient does not exist.[4]
However, even if a function is continuous at a point, it may not be differentiable there. For example, the absolute value function y = |x| is continuous at x = 0, but it is not differentiable there. If h is positive, then the slope of the secant line from 0 to h is one, whereas if h is negative, then the slope of the secant line from 0 to h is negative one. This can be seen graphically as a "kink" or a "cusp" in the graph at x = 0. Even a function with a smooth graph is not differentiable at a point where its tangent is vertical: For instance, the function y = 3√x is not differentiable at x = 0.
In summary: for a function ƒ to have a derivative it is necessary for the function ƒ to be continuous, but continuity alone is not sufficient.
Most functions that occur in practice have derivatives at all points or at almost every point. Early in the history of calculus, many mathematicians assumed that a continuous function was differentiable at most points. Under mild conditions, for example if the function is a monotone function or a Lipschitz function, this is true. However, in 1872 Weierstrass found the first example of a function that is continuous everywhere but differentiable nowhere. This example is now known as the Weierstrass function. In 1931, Stefan Banach proved that the set of functions that have a derivative at some point is a meager set in the space of all continuous functions.[5] Informally, this means that hardly any continuous functions have a derivative at even one point.
The derivative as a function
Let ƒ be a function that has a derivative at every point a in the domain of ƒ. Because every point a has a derivative, there is a function that sends the point a to the derivative of ƒ at a. This function is written f′(x) and is called the derivative function or the derivative of ƒ. The derivative of ƒ collects all the derivatives of ƒ at all the points in the domain of ƒ.
Sometimes ƒ has a derivative at most, but not all, points of its domain. The function whose value at a equals f′(a) whenever f′(a) is defined and elsewhere is undefined is also called the derivative of ƒ. It is still a function, but its domain is strictly smaller than the domain of ƒ.
Using this idea, differentiation becomes a function of functions: The derivative is an operator whose domain is the set of all functions that have derivatives at every point of their domain and whose range is a set of functions. If we denote this operator by D, then D(ƒ) is the function f′(x). Since D(ƒ) is a function, it can be evaluated at a point a. By the definition of the derivative function, D(ƒ)(a) = f′(a).
For comparison, consider the doubling function ƒ(x) =2x; ƒ is a real-valued function of a real number, meaning that it takes numbers as inputs and has numbers as outputs:
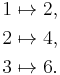
The operator D, however, is not defined on individual numbers. It is only defined on functions:
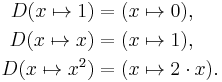
Because the output of D is a function, the output of D can be evaluated at a point. For instance, when D is applied to the squaring function,
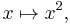
D outputs the doubling function,
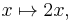
which we named ƒ(x). This output function can then be evaluated to get ƒ(1) = 2, ƒ(2) = 4, and so on.
Higher derivatives
Let ƒ be a differentiable function, and let f′(x) be its derivative. The derivative of f′(x) (if it has one) is written f′′(x) and is called the second derivative of ƒ. Similarly, the derivative of a second derivative, if it exists, is written f′′′(x) and is called the third derivative of ƒ. These repeated derivatives are called higher-order derivatives.
If x(t) represents the position of an object at time t, then the higher-order derivatives of x have physical interpretations. The second derivative of x is the derivative of x′(t), the velocity, and by definition this is the object's acceleration. The third derivative of x is defined to be the jerk, and the fourth derivative is defined to be the jounce.
A function ƒ need not have a derivative, for example, if it is not continuous. Similarly, even if ƒ does have a derivative, it may not have a second derivative. For example, let
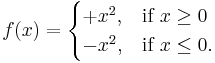
Calculation shows that ƒ is a differentiable function whose derivative is
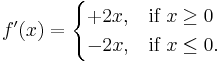
f′(x) is twice the absolute value function, and it does not have a derivative at zero. Similar examples show that a function can have k derivatives for any non-negative integer k but no (k + 1)-order derivative. A function that has k successive derivatives is called k times differentiable. If in addition the kth derivative is continuous, then the function is said to be of differentiability class Ck. (This is a stronger condition than having k derivatives. For an example, see differentiability class.) A function that has infinitely many derivatives is called infinitely differentiable or smooth.
On the real line, every polynomial function is infinitely differentiable. By standard differentiation rules, if a polynomial of degree n is differentiated n times, then it becomes a constant function. All of its subsequent derivatives are identically zero. In particular, they exist, so polynomials are smooth functions.
The derivatives of a function ƒ at a point x provide polynomial approximations to that function near x. For example, if ƒ is twice differentiable, then
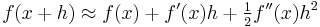
in the sense that
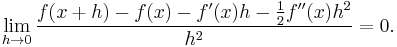
If ƒ is infinitely differentiable, then this is the beginning of the Taylor series for ƒ.
Inflection point
A point where the second derivative of a function changes sign is called an inflection point.[6] At an inflection point, the second derivative may be zero, as in the case of the inflection point x=0 of the function y=x3, or it may fail to exist, as in the case of the inflection point x=0 of the function y=x1/3. At an inflection point, a function switches from being a convex function to being a concave function or vice versa.
Notations for differentiation
Leibniz's notation
The notation for derivatives introduced by Gottfried Leibniz is one of the earliest. It is still commonly used when the equation y = ƒ(x) is viewed as a functional relationship between dependent and independent variables. Then the first derivative is denoted by
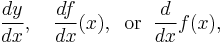
and was once thought of as an infinitesimal quotient. Higher derivatives are expressed using the notation
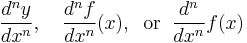
for the nth derivative of y = ƒ(x) (with respect to x). These are abbreviations for multiple applications of the derivative operator. For example,
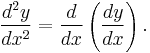
With Leibniz's notation, we can write the derivative of y at the point x = a in two different ways:
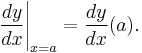
Leibniz's notation allows one to specify the variable for differentiation (in the denominator). This is especially relevant for partial differentiation. It also makes the chain rule easy to remember:[7]
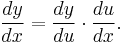
Lagrange's notation
Sometimes referred to as prime notation,[8] one of the most common modern notations for differentiation is due to Joseph-Louis Lagrange and uses the prime mark, so that the derivative of a function ƒ(x) is denoted ƒ′(x) or simply ƒ′. Similarly, the second and third derivatives are denoted
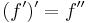 and
and 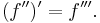
To denote the number of derivatives beyond this point, some authors use Roman numerals in superscript, whereas others place the number in parentheses:
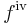 or
or 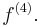
The latter notation generalizes to yield the notation ƒ (n) for the nth derivative of ƒ — this notation is most useful when we wish to talk about the derivative as being a function itself, as in this case the Leibniz notation can become cumbersome.
Newton's notation
Newton's notation for differentiation, also called the dot notation, places a dot over the function name to represent a time derivative. If y = ƒ(t), then
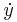 and
and 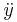
denote, respectively, the first and second derivatives of y with respect to t. This notation is used exclusively for time derivatives, meaning that the independent variable of the function represents time. It is very common in physics and in mathematical disciplines connected with physics such as differential equations. While the notation becomes unmanageable for high-order derivatives, in practice only very few derivatives are needed.
Euler's notation
Euler's notation uses a differential operator D, which is applied to a function ƒ to give the first derivative Df. The second derivative is denoted D2ƒ, and the nth derivative is denoted Dnƒ.
If y = ƒ(x) is a dependent variable, then often the subscript x is attached to the D to clarify the independent variable x. Euler's notation is then written
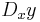 or
or 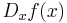 ,
,
although this subscript is often omitted when the variable x is understood, for instance when this is the only variable present in the expression.
Euler's notation is useful for stating and solving linear differential equations.
Computing the derivative
The derivative of a function can, in principle, be computed from the definition by considering the difference quotient, and computing its limit. In practice, once the derivatives of a few simple functions are known, the derivatives of other functions are more easily computed using rules for obtaining derivatives of more complicated functions from simpler ones.
Derivatives of elementary functions
Most derivative computations eventually require taking the derivative of some common functions. The following incomplete list gives some of the most frequently used functions of a single real variable and their derivatives.
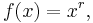
where r is any real number, then
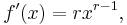
wherever this function is defined. For example, if 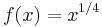 , then
, then
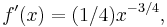
and the derivative function is defined only for positive x, not for x = 0. When r = 0, this rule implies that f′(x) is zero for x ≠ 0, which is almost the constant rule (stated below).
- Exponential and logarithmic functions:
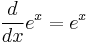
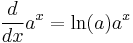
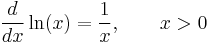
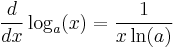
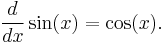
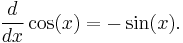
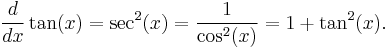
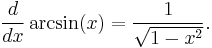
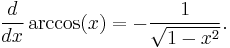
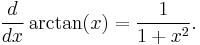
Rules for finding the derivative
In many cases, complicated limit calculations by direct application of Newton's difference quotient can be avoided using differentiation rules. Some of the most basic rules are the following.
- Constant rule: if ƒ(x) is constant, then
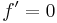
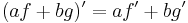 for all functions ƒ and g and all real numbers a and b.
for all functions ƒ and g and all real numbers a and b.
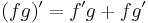 for all functions ƒ and g.
for all functions ƒ and g.
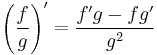 for all functions ƒ and g where g ≠ 0.
for all functions ƒ and g where g ≠ 0.
- Chain rule: If
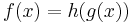 , then
, then
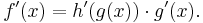
Example computation
The derivative of
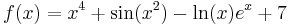
is
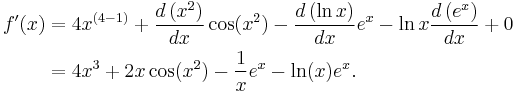
Here the second term was computed using the chain rule and third using the product rule. The known derivatives of the elementary functions x2, x4, sin(x), ln(x) and exp(x) = ex, as well as the constant 7, were also used.
Derivatives in higher dimensions
Derivatives of vector valued functions
A vector-valued function y(t) of a real variable sends real numbers to vectors in some vector space Rn. A vector-valued function can be split up into its coordinate functions y1(t), y2(t), …, yn(t), meaning that y(t) = (y1(t), ..., yn(t)). This includes, for example, parametric curves in R2 or R3. The coordinate functions are real valued functions, so the above definition of derivative applies to them. The derivative of y(t) is defined to be the vector, called the tangent vector, whose coordinates are the derivatives of the coordinate functions. That is,
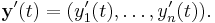
Equivalently,
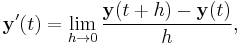
if the limit exists. The subtraction in the numerator is subtraction of vectors, not scalars. If the derivative of y exists for every value of t, then y′ is another vector valued function.
If e1, …, en is the standard basis for Rn, then y(t) can also be written as y1(t)e1 + … + yn(t)en. If we assume that the derivative of a vector-valued function retains the linearity property, then the derivative of y(t) must be

because each of the basis vectors is a constant.
This generalization is useful, for example, if y(t) is the position vector of a particle at time t; then the derivative y′(t) is the velocity vector of the particle at time t.
Partial derivatives
Suppose that ƒ is a function that depends on more than one variable. For instance,
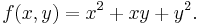
ƒ can be reinterpreted as a family of functions of one variable indexed by the other variables:
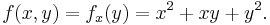
In other words, every value of x chooses a function, denoted fx, which is a function of one real number.[9] That is,
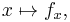
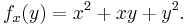
Once a value of x is chosen, say a, then f(x,y) determines a function fa that sends y to a² + ay + y²:
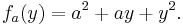
In this expression, a is a constant, not a variable, so fa is a function of only one real variable. Consequently the definition of the derivative for a function of one variable applies:
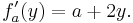
The above procedure can be performed for any choice of a. Assembling the derivatives together into a function gives a function that describes the variation of ƒ in the y direction:
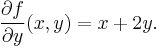
This is the partial derivative of ƒ with respect to y. Here ∂ is a rounded d called the partial derivative symbol. To distinguish it from the letter d, ∂ is sometimes pronounced "der", "del", or "partial" instead of "dee".
In general, the partial derivative of a function ƒ(x1, …, xn) in the direction xi at the point (a1 …, an) is defined to be:
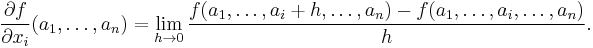
In the above difference quotient, all the variables except xi are held fixed. That choice of fixed values determines a function of one variable
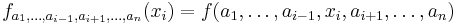
and, by definition,
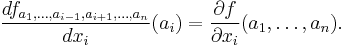
In other words, the different choices of a index a family of one-variable functions just as in the example above. This expression also shows that the computation of partial derivatives reduces to the computation of one-variable derivatives.
An important example of a function of several variables is the case of a scalar-valued function ƒ(x1,...xn) on a domain in Euclidean space Rn (e.g., on R² or R³). In this case ƒ has a partial derivative ∂ƒ/∂xj with respect to each variable xj. At the point a, these partial derivatives define the vector
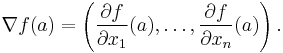
This vector is called the gradient of ƒ at a. If ƒ is differentiable at every point in some domain, then the gradient is a vector-valued function ∇ƒ that takes the point a to the vector ∇f(a). Consequently the gradient determines a vector field.
Directional derivatives
If ƒ is a real-valued function on Rn, then the partial derivatives of ƒ measure its variation in the direction of the coordinate axes. For example, if ƒ is a function of x and y, then its partial derivatives measure the variation in ƒ in the x direction and the y direction. They do not, however, directly measure the variation of ƒ in any other direction, such as along the diagonal line y = x. These are measured using directional derivatives. Choose a vector
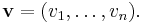
The directional derivative of ƒ in the direction of v at the point x is the limit
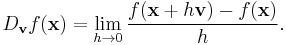
In some cases it may be easier to compute or estimate the directional derivative after changing the length of the vector. Often this is done to turn the problem into the computation of a directional derivative in the direction of a unit vector. To see how this works, suppose that v = λu. Substitute h = k/λ into the difference quotient. The difference quotient becomes:
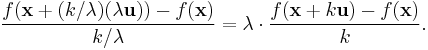
This is λ times the difference quotient for the directional derivative of f with respect to u. Furthermore, taking the limit as h tends to zero is the same as taking the limit as k tends to zero because h and k are multiples of each other. Therefore Dv(ƒ) = λDu(ƒ). Because of this rescaling property, directional derivatives are frequently considered only for unit vectors.
If all the partial derivatives of ƒ exist and are continuous at x, then they determine the directional derivative of ƒ in the direction v by the formula:
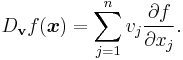
This is a consequence of the definition of the total derivative. It follows that the directional derivative is linear in v, meaning that Dv + w(ƒ) = Dv(ƒ) + Dw(ƒ).
The same definition also works when ƒ is a function with values in Rm. The above definition is applied to each component of the vectors. In this case, the directional derivative is a vector in Rm.
Total derivative, total differential and Jacobian matrix
When ƒ is a function from an open subset of Rn to Rm, then the directional derivative of ƒ in a chosen direction is the best linear approximation to ƒ at that point and in that direction. But when n > 1, no single directional derivative can give a complete picture of the behavior of ƒ. The total derivative, also called the (total) differential, gives a complete picture by considering all directions at once. That is, for any vector v starting at a, the linear approximation formula holds:
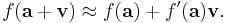
Just like the single-variable derivative, ƒ ′(a) is chosen so that the error in this approximation is as small as possible.
If n and m are both one, then the derivative ƒ ′(a) is a number and the expression ƒ ′(a)v is the product of two numbers. But in higher dimensions, it is impossible for ƒ ′(a) to be a number. If it were a number, then ƒ ′(a)v would be a vector in Rn while the other terms would be vectors in Rm, and therefore the formula would not make sense. For the linear approximation formula to make sense, ƒ ′(a) must be a function that sends vectors in Rn to vectors in Rm, and ƒ ′(a)v must denote this function evaluated at v.
To determine what kind of function it is, notice that the linear approximation formula can be rewritten as
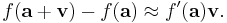
Notice that if we choose another vector w, then this approximate equation determines another approximate equation by substituting w for v. It determines a third approximate equation by substituting both w for v and a + v for a. By subtracting these two new equations, we get
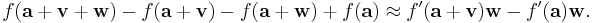
If we assume that v is small and that the derivative varies continuously in a, then ƒ ′(a + v) is approximately equal to ƒ ′(a), and therefore the right-hand side is approximately zero. The left-hand side can be rewritten in a different way using the linear approximation formula with v + w substituted for v. The linear approximation formula implies:
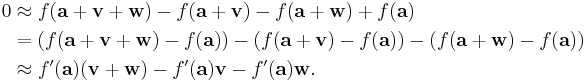
This suggests that ƒ ′(a) is a linear transformation from the vector space Rn to the vector space Rm. In fact, it is possible to make this a precise derivation by measuring the error in the approximations. Assume that the error in these linear approximation formula is bounded by a constant times ||v||, where the constant is independent of v but depends continuously on a. Then, after adding an appropriate error term, all of the above approximate equalities can be rephrased as inequalities. In particular, ƒ ′(a) is a linear transformation up to a small error term. In the limit as v and w tend to zero, it must therefore be a linear transformation. Since we define the total derivative by taking a limit as v goes to zero, ƒ ′(a) must be a linear transformation.
In one variable, the fact that the derivative is the best linear approximation is expressed by the fact that it is the limit of difference quotients. However, the usual difference quotient does not make sense in higher dimensions because it is not usually possible to divide vectors. In particular, the numerator and denominator of the difference quotient are not even in the same vector space: The numerator lies in the codomain Rm while the denominator lies in the domain Rn. Furthermore, the derivative is a linear transformation, a different type of object from both the numerator and denominator. To make precise the idea that ƒ ′ (a) is the best linear approximation, it is necessary to adapt a different formula for the one-variable derivative in which these problems disappear. If ƒ : R → R, then the usual definition of the derivative may be manipulated to show that the derivative of ƒ at a is the unique number ƒ ′(a) such that
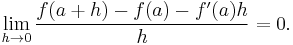
This is equivalent to
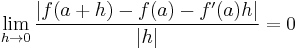
because the limit of a function tends to zero if and only if the limit of the absolute value of the function tends to zero. This last formula can be adapted to the many-variable situation by replacing the absolute values with norms.
The definition of the total derivative of ƒ at a, therefore, is that it is the unique linear transformation ƒ ′(a) : Rn → Rm such that
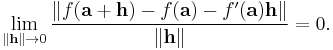
Here h is a vector in Rn, so the norm in the denominator is the standard length on Rn. However, ƒ′(a)h is a vector in Rm, and the norm in the numerator is the standard length on Rm. If v is a vector starting at a, then ƒ ′(a)v is called the pushforward of v by ƒ and is sometimes written ƒ*v.
If the total derivative exists at a, then all the partial derivatives and directional derivatives of ƒ exist at a, and for all v, ƒ ′(a)v is the directional derivative of ƒ in the direction v. If we write ƒ using coordinate functions, so that ƒ = (ƒ1, ƒ2, ..., ƒm), then the total derivative can be expressed using the partial derivatives as a matrix. This matrix is called the Jacobian matrix of ƒ at a:
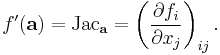
The existence of the total derivative ƒ′(a) is strictly stronger than the existence of all the partial derivatives, but if the partial derivatives exist and are continuous, then the total derivative exists, is given by the Jacobian, and depends continuously on a.
The definition of the total derivative subsumes the definition of the derivative in one variable. That is, if ƒ is a real-valued function of a real variable, then the total derivative exists if and only if the usual derivative exists. The Jacobian matrix reduces to a 1×1 matrix whose only entry is the derivative ƒ′(x). This 1×1 matrix satisfies the property that ƒ(a + h) − ƒ(a) − ƒ ′(a)h is approximately zero, in other words that
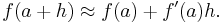
Up to changing variables, this is the statement that the function 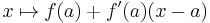 is the best linear approximation to ƒ at a.
is the best linear approximation to ƒ at a.
The total derivative of a function does not give another function in the same way as the one-variable case. This is because the total derivative of a multivariable function has to record much more information than the derivative of a single-variable function. Instead, the total derivative gives a function from the tangent bundle of the source to the tangent bundle of the target.
The natural analog of second, third, and higher-order total derivatives is not a linear transformation, is not a function on the tangent bundle, and is not built by repeatedly taking the total derivative. The analog of a higher-order derivative, called a jet, cannot be a linear transformation because higher-order derivatives reflect subtle geometric information, such as concavity, which cannot be described in terms of linear data such as vectors. It cannot be a function on the tangent bundle because the tangent bundle only has room for the base space and the directional derivatives. Because jets capture higher-order information, they take as arguments additional coordinates representing higher-order changes in direction. The space determined by these additional coordinates is called the jet bundle. The relation between the total derivative and the partial derivatives of a function is paralleled in the relation between the kth order jet of a function and its partial derivatives of order less than or equal to k.
Generalizations
The concept of a derivative can be extended to many other settings. The common thread is that the derivative of a function at a point serves as a linear approximation of the function at that point.
- An important generalization of the derivative concerns complex functions of complex variables, such as functions from (a domain in) the complex numbers C to C. The notion of the derivative of such a function is obtained by replacing real variables with complex variables in the definition. If C is identified with R² by writing a complex number z as x + i y, then a differentiable function from C to C is certainly differentiable as a function from R² to R² (in the sense that its partial derivatives all exist), but the converse is not true in general: the complex derivative only exists if the real derivative is complex linear and this imposes relations between the partial derivatives called the Cauchy Riemann equations — see holomorphic functions.
- Another generalization concerns functions between differentiable or smooth manifolds. Intuitively speaking such a manifold M is a space that can be approximated near each point x by a vector space called its tangent space: the prototypical example is a smooth surface in R³. The derivative (or differential) of a (differentiable) map ƒ: M → N between manifolds, at a point x in M, is then a linear map from the tangent space of M at x to the tangent space of N at ƒ(x). The derivative function becomes a map between the tangent bundles of M and N. This definition is fundamental in differential geometry and has many uses — see pushforward (differential) and pullback (differential geometry).
- Differentiation can also be defined for maps between infinite dimensional vector spaces such as Banach spaces and Fréchet spaces. There is a generalization both of the directional derivative, called the Gâteaux derivative, and of the differential, called the Fréchet derivative.
- One deficiency of the classical derivative is that not very many functions are differentiable. Nevertheless, there is a way of extending the notion of the derivative so that all continuous functions and many other functions can be differentiated using a concept known as the weak derivative. The idea is to embed the continuous functions in a larger space called the space of distributions and only require that a function is differentiable "on average".
- The properties of the derivative have inspired the introduction and study of many similar objects in algebra and topology — see, for example, differential algebra.
- The discrete equivalent of differentiation is finite differences. The study of differential calculus is unified with the calculus of finite differences in time scale calculus.
- Also see arithmetic derivative.
See also
- Applications of derivatives
- Automatic differentiation
- Differentiability class
- Differintegral
- Generalizations of the derivative
- Integral
- Linearization
- Multiplicative inverse
- Numerical differentiation
- Symmetric derivative
- Differentiation rules
Notes
- ^ Differential calculus, as discussed in this article, is a very well-established mathematical discipline for which there are many sources. Almost all of the material in this article can be found in Apostol 1967, Apostol 1969, and Spivak 1994.
- ^ Spivak 1994, chapter 10.
- ^ See Differential (infinitesimal) for an overview. Further approaches include the Radon–Nikodym theorem, and the universal derivation (see Kähler differential).
- ^ Despite this, it is still possible to take the derivative in the sense of distributions. The result is nine times the Dirac measure centered at a.
- ^ Banach, S. (1931), "Uber die Baire'sche Kategorie gewisser Funktionenmengen", Studia. Math. (3): 174–179.. Cited by Hewitt, E and Stromberg, K (1963), Real and abstract analysis, Springer-Verlag, Theorem 17.8
- ^ Apostol 1967, §4.18
- ^ In the formulation of calculus in terms of limits, the du symbol has been assigned various meanings by various authors. Some authors do not assign a meaning to du by itself, but only as part of the symbol du/dx. Others define "dx" as an independent variable, and define du by du = dx•ƒ′ (x). In non-standard analysis du is defined as an infinitesimal. It is also interpreted as the exterior derivative du of a function u. See differential (infinitesimal) for further information.
- ^ [1]
- ^ This can also be expressed as the adjointness between the product space and function space constructions.
References
- Anton, Howard; Bivens, Irl; Davis, Stephen (February 2, 2005), Calculus: Early Transcendentals Single and Multivariable (8th ed.), New York: Wiley, ISBN 978-0-471-47244-5
- Apostol, Tom M. (June 1967), Calculus, Vol. 1: One-Variable Calculus with an Introduction to Linear Algebra, 1 (2nd ed.), Wiley, ISBN 978-0-471-00005-1
- Apostol, Tom M. (June 1969), Calculus, Vol. 2: Multi-Variable Calculus and Linear Algebra with Applications, 1 (2nd ed.), Wiley, ISBN 978-0-471-00007-5
- Courant, Richard; John, Fritz (December 22, 1998), Introduction to Calculus and Analysis, Vol. 1, Springer-Verlag, ISBN 978-3-540-65058-4
- Eves, Howard (January 2, 1990), An Introduction to the History of Mathematics (6th ed.), Brooks Cole, ISBN 978-0-03-029558-4
- Larson, Ron; Hostetler, Robert P.; Edwards, Bruce H. (February 28, 2006), Calculus: Early Transcendental Functions (4th ed.), Houghton Mifflin Company, ISBN 978-0-618-60624-5
- Spivak, Michael (September 1994), Calculus (3rd ed.), Publish or Perish, ISBN 978-0-914098-89-8
- Stewart, James (December 24, 2002), Calculus (5th ed.), Brooks Cole, ISBN 978-0-534-39339-7
- Thompson, Silvanus P. (September 8, 1998), Calculus Made Easy (Revised, Updated, Expanded ed.), New York: St. Martin's Press, ISBN 978-0-312-18548-0
Online books
- Crowell, Benjamin (2003), Calculus, http://www.lightandmatter.com/calc/
- Garrett, Paul (2004), Notes on First-Year Calculus, University of Minnesota, http://www.math.umn.edu/~garrett/calculus/
- Hussain, Faraz (2006), Understanding Calculus, http://www.understandingcalculus.com/
- Keisler, H. Jerome (2000), Elementary Calculus: An Approach Using Infinitesimals, http://www.math.wisc.edu/~keisler/calc.html
- Mauch, Sean (2004), Unabridged Version of Sean's Applied Math Book, http://www.its.caltech.edu/~sean/book/unabridged.html
- Sloughter, Dan (2000), Difference Equations to Differential Equations, http://synechism.org/drupal/de2de/
- Strang, Gilbert (1991), Calculus, http://ocw.mit.edu/ans7870/resources/Strang/strangtext.htm
- Stroyan, Keith D. (1997), A Brief Introduction to Infinitesimal Calculus, http://www.math.uiowa.edu/~stroyan/InfsmlCalculus/InfsmlCalc.htm
- Wikibooks, Calculus, http://en.wikibooks.org/wiki/Calculus
Web pages
- Khan Academy: Derivative lesson 1
- Weisstein, Eric W. "Derivative." From MathWorld
- Derivatives of Trigonometric functions, UBC
- Solved Problems in Derivatives